In Part 2 we streamed call audio out of FreeSWITCH over a WebSocket. In Part 3 we sent that audio to Deepgram and got real-time transcripts back. Now we close the loop: caller speaks → transcript → LLM → synthesized speech → caller hears the response. A working voice agent on a stock FreeSWITCH install in under 400 lines of Node.
This post will be longer than Parts 1-3 because closing the loop surfaces real engineering problems — codec mismatches, playback ordering, utterance boundaries, conversation memory — that one-way streaming doesn’t expose. I’ll show you the specific dead ends so you don’t have to walk down them yourself.
What you’ll have at the end
A FreeSWITCH extension at 9999 that, when you call it from your softphone:
- Greets you with “Hi there! How can I help you today?”
- Listens to whatever you say
- Sends your transcript to GPT-4o-mini with conversation memory
- Speaks the response back to you using Deepgram Aura-2
- Repeats until you hang up
Median first-audio latency: Expect about 1.4 seconds from the moment you stop speaking to the moment you hear the agent. While it’s not blindingly fast, it feels conversational and entirely usable. That said, we’ll need to do some extra tuning to improve how it handles things like interruptions and barge-in. Utilizing an existing framework like Pipecat—or using a vendor that has already solved these challenges—is starting to look like a good option right about now. But hey, I like to do things the hard way!
The architecture decision that wasted a week
Tutorials about voice AI on FreeSWITCH almost always reach for mod_audio_stream’s bidirectional playback feature: send TTS audio back through the same WebSocket the module uses for outbound audio, and the module plays it into the call. Clean. Symmetric. One protocol.
In my testing, it simply didn’t work reliably. It’s entirely possible I missed something, so if you’ve gotten it to work, please let me know in the comments!
The v1.0.3 binary advertises audioDataType: “raw” / “pcmu” / “pcma” for playback, has all the right symbols (STREAM_PLAYBACK, chunk_played, queue_completed), and parses the JSON envelopes correctly — you can see it write .tmp.r8 files for every chunk you send. But the playback engine doesn’t fire chunks into the call audio. No chunk_played events. No queue_completed events. The caller hears nothing.
The maintainer’s documentation says playback “must stream at 16kHz.” We tried 16kHz. I tried 8kHz. I tried raw, pcmu, and pcma. I tried with and without STREAM_PLAYBACK=true. I tried with the channel codec pinned to PCMU and with G.722 negotiation. I sent a clean 1-second 440Hz tone in a single chunk to rule out chunking issues. The module decoded everything, wrote files, and played nothing.
It seems I wasn’t alone. Issue #56, #87, #104, and #119 all describe variations of the same failure. None resolved.
So this post does what works: mod_audio_stream still handles caller-audio-in (it’s rock solid for that), but for agent-audio-out, I use FreeSWITCH’s built-in uuid_broadcast command via the Event Socket. Less elegant. More moving parts. Works on every FreeSWITCH install.
If mod_audio_stream’s playback path eventually stabilizes, you can swap it in — the rest of the architecture is the same.
The data flow
Caller’s voice Agent’s voice
↓ ↑
[FreeSWITCH channel]──┬──────[uuid_broadcast WAV]
│ ↑
↓ [/tmp/agent-N.wav]
[mod_audio_stream] ↑
↓ [Node writes WAV]
[WebSocket binary] ↑
↓ [Deepgram TTS]
[Node server] ↑
↓ [OpenAI streaming]
[Deepgram STT] ↑
↓ [transcript]
[transcript]──────────────────┘
Two separate paths:
Caller → agent (STT path): Same as Part 3. mod_audio_stream forks the call’s audio into a WebSocket. Our Node server forwards binary frames to Deepgram. Deepgram streams transcripts back over its own WebSocket.
Agent → caller (TTS path, new in Part 4): Node opens an Event Socket connection to FreeSWITCH on port 8021, authenticates with the password from /etc/fs_cli.conf. When the LLM produces a response, Node synthesizes it to a WAV file with Deepgram TTS, writes it to /tmp, and tells FreeSWITCH uuid_broadcast <channel-uuid> /tmp/file.wav aleg. FreeSWITCH’s standard playback machinery handles codec negotiation and plays the WAV into the call.
The channel UUID is the bridge between these two paths. The Lua dialplan script sends it as the first text frame on the WebSocket, so Node knows which channel to broadcast to.
The full stack
Cost-conscious choice: single-vendor where possible.
| Component | Choice | Why |
| STT | Deepgram Nova-3 | Validated in Part 3. ~$0.0058/min streaming. |
| LLM | OpenAI GPT-4o-mini | $0.150 / $0.600 per 1M tokens. Fast time-to-first-token. |
| TTS | Deepgram Aura-2 (aura-2-thalia-en) | $0.030 / 1K characters. Same vendor as STT means one API key, one billing relationship. Smaller voice library than ElevenLabs but acceptable tradeoff. |
The total cost for a 5-minute conversation is roughly $0.05- $ 0.08, depending on how chatty the agent gets. The Deepgram side dominates.
Step 1: Install dependencies and the v1.0.0 binary
If you’ve completed Part 3, you already have everything except models (the Node ESL client) and OpenAI.
From the /opt/audio-fork-server directory:
cd /opt/audio-fork-server
sudo npm install modesl@1.2.1 openai@^4Make sure you’re on mod_audio_stream v1.0.0, not v1.0.3 — the community v1.0.0 build is what we recommend for the STT-only use case, and downgrading sidesteps any v1.0.3 license messaging:
cd /tmp
wget https://github.com/amigniter/mod_audio_stream/releases/download/v1.0.0/mod-audio-stream_1.0.0_amd64.deb
sudo apt install --reinstall --allow-downgrades ./mod-audio-stream_1.0.0_amd64.deb
sudo fs_cli -x "unload mod_audio_stream"
sudo fs_cli -x "load mod_audio_stream"Step 2: Get the ESL password
If you used my hardening script, it set the ESL password to a strong random value in /etc/fs_cli.conf. We need to read it once and export it as an environment variable so the Node server can use it:
sudo cat /etc/fs_cli.conf | grep password# Copy the value, then:
export FS_ESL_PASSWORD="paste-the-value-here"The Event Socket is bound to 127.0.0.1 only (also from the hardening pass), so this connection never crosses a network. We’re not adding any public attack surface.
While you’re at it, set the Deepgram and OpenAI keys:
export DEEPGRAM_API_KEY="dg-..."
export OPENAI_API_KEY="sk-..."For real deployments, these belong in a systemd unit’s EnvironmentFile or a proper password vault. Part 5 covers that.
Step 3: The dialplan
Same extension as Part 3. Drop into /etc/freeswitch/dialplan/default/99_audio_stream_test.xml:
<include>
<extension name="audio_stream_test">
<condition field="destination_number" expression="^9999$">
<action application="answer"/>
<action application="sleep" data="500"/>
<action application="set" data="STREAM_BUFFER_SIZE=20"/>
<action application="lua" data="audio_stream_start.lua"/>
<action application="park"/>
</condition>
</extension>
</include>Then reload XML:
sudo fs_cli -x "reloadxml"The STREAM_BUFFER_SIZE=20 is buffered ms, not bytes — 20ms gives mod_audio_stream a small jitter buffer that smooths over network-stack timing without adding noticeable latency.
Step 4: The Lua starter
/usr/share/freeswitch/scripts/audio_stream_start.lua:
local uuid = session:get_uuid()
local metadata = '{"type":"start","uuid":"' .. uuid .. '"}'
local result = freeswitch.API():executeString(
"uuid_audio_stream " .. uuid .. " start ws://127.0.0.1:8080 mono 8k " .. metadata
)
freeswitch.consoleLog("INFO", "audio_stream start: " .. tostring(result) .. "\n")Two things to note. First, we use mono 8k (the documented form) rather than mono 8000. Both work, but 8k is what the module’s parser expects. Second, the JSON metadata at the end — it’s an optional argument to the start command that mod_audio_stream forwards to the WebSocket as the first text frame. We use it to tell the Node server which channel UUID to broadcast WAV files to. Without it, our server would have no way to know which call to play audio into.
Step 5: The server, walked through
This is where the real work lives. I’ll walk through the parts that deserve attention so you understand what’s going on, then in Step 5b I’ll give you the complete file to copy in one shot.
The setup:
const fs = require('fs');
const { WebSocketServer } = require('ws');
const { DeepgramClient } = require('@deepgram/sdk');
const OpenAI = require('openai');
const esl = require('modesl');
const PORT = 8080;
const SAMPLE_RATE = 8000;
const CHANNELS = 1;
const DG_KEY = process.env.DEEPGRAM_API_KEY;
const OPENAI_KEY = process.env.OPENAI_API_KEY;
const ESL_PASS = process.env.FS_ESL_PASSWORD;
if (!DG_KEY) { console.error('ERROR: DEEPGRAM_API_KEY not set.'); process.exit(1); }
if (!OPENAI_KEY) { console.error('ERROR: OPENAI_API_KEY not set.'); process.exit(1); }
if (!ESL_PASS) { console.error('ERROR: FS_ESL_PASSWORD not set.'); process.exit(1); }
const deepgram = new DeepgramClient({ apiKey: DG_KEY });
const openai = new OpenAI({ apiKey: OPENAI_KEY });
const wss = new WebSocketServer({ port: PORT });
const SYSTEM_PROMPT =
'You are a helpful voice agent. Keep responses brief and conversational — ' +
'typically 1-2 sentences. Speak naturally as if on a phone call. ' +
'Avoid markdown, lists, or formatting.';
const GREETING = 'Hi there! How can I help you today?';Standard setup. Three required environment variables, fail-fast if any is missing. The system prompt is opinionated about brevity — voice agents that produce paragraph-long responses feel terrible.
The ESL connection is shared across all calls (a single Node process can handle many concurrent calls; in this tutorial we only test one at a time but the architecture supports more):
let eslConn = null;
let eslReady = false;
function connectEsl() {
return new Promise((resolve, reject) => {
const conn = new esl.Connection('127.0.0.1', 8021, ESL_PASS, () => {
console.log('ESL connected to FreeSWITCH');
conn.events('plain', 'PLAYBACK_STOP CHANNEL_HANGUP', () => {
eslConn = conn;
eslReady = true;
resolve(conn);
});
});
conn.on('error', (err) => {
console.error('ESL error:', err);
eslReady = false;
reject(err);
});
});
}
function eslBgapi(cmd) {
return new Promise((resolve, reject) => {
if (!eslReady) return reject(new Error('ESL not ready'));
eslConn.bgapi(cmd, (res) => resolve(res?.getBody?.() || ''));
});
}We subscribe to PLAYBACK_STOP and CHANNEL_HANGUP events. The first tells us when a queued WAV finishes playing. The second tells us when a call has ended.
The WAV writer is identical to Part 2:
function writeWav(filepath, pcm, rate, channels, bits) {
const byteRate = rate * channels * (bits / 8);
const blockAlign = channels * (bits / 8);
const header = Buffer.alloc(44);
header.write('RIFF', 0);
header.writeUInt32LE(36 + pcm.length, 4);
header.write('WAVE', 8);
header.write('fmt ', 12);
header.writeUInt32LE(16, 16);
header.writeUInt16LE(1, 20);
header.writeUInt16LE(channels, 22);
header.writeUInt32LE(rate, 24);
header.writeUInt32LE(byteRate, 28);
header.writeUInt16LE(blockAlign, 32);
header.writeUInt16LE(bits, 34);
header.write('data', 36);
header.writeUInt32LE(pcm.length, 40);
fs.writeFileSync(filepath, Buffer.concat([header, pcm]));
}The phrase synthesizer opens a fresh Deepgram TTS connection per phrase, sends the text, waits for the Flushed signal, and writes the result to disk:
async function synthesizePhraseToWav(text, callId, turnN, phraseN) {
const tts = await deepgram.speak.v1.connect({
model: 'aura-2-thalia-en',
encoding: 'linear16',
sample_rate: SAMPLE_RATE,
});
const audioChunks = [];
let resolveFlushed;
const flushedPromise = new Promise(r => { resolveFlushed = r; });
tts.on('open', () => {
tts.socket.addEventListener('message', async (event) => {
const data = event.data;
if (data instanceof Blob) {
audioChunks.push(Buffer.from(await data.arrayBuffer()));
} else if (typeof data === 'string') {
try {
const msg = JSON.parse(data);
if (msg.type === 'Flushed') {
tts.socket.close();
resolveFlushed();
}
} catch {}
}
});
});
tts.on('error', (err) => console.error(`[${callId}] TTS error:`, err));
tts.connect();
await tts.waitForOpen();
tts.socket.send(JSON.stringify({ type: 'Speak', text }));
tts.socket.send(JSON.stringify({ type: 'Flush' }));
await flushedPromise;
const wavPath = `/tmp/agent-${callId}-${turnN}-${phraseN}.wav`;
writeWav(wavPath, Buffer.concat(audioChunks), SAMPLE_RATE, CHANNELS, 16);
return wavPath;
}A note on the Deepgram SDK v5 surface that took me hours to figure out and is essentially undocumented at the time of writing: the wrapper’s .on(‘message’) handler mangles binary frames into empty {} objects. You must bypass the wrapper and listen on the underlying socket via tts.socket.addEventListener(‘message’, …). Audio chunks arrive as Blob objects (browser-style binary, not Node Buffers), so you have to convert them with Buffer.from(await blob.arrayBuffer()). The wrapper also has no flush() method — you send the raw control frames as JSON: {“type”:”Speak”,”text”:”…”} to add text and {“type”:”Flush”} to force synthesis.
The playback queue is the most subtle part of the architecture. Here’s the version that actually works:
function makePlaybackQueue(callId, channelUuid) {
const playableQueue = [];
const waiting = new Map();
let playing = false;
let pendingSynth = 0;
let nextExpected = 1;
let onIdle = null;
function checkIdle() {
if (!playing &&
playableQueue.length === 0 &&
pendingSynth === 0 &&
waiting.size === 0 &&
onIdle) {
const cb = onIdle;
onIdle = null;
cb();
}
}
function drainWaiting() {
while (waiting.has(nextExpected)) {
const entry = waiting.get(nextExpected);
waiting.delete(nextExpected);
playableQueue.push(entry);
nextExpected++;
}
}
async function broadcastAndWait(wavPath) {
const playbackComplete = new Promise((resolve) => {
const listener = (evt) => {
const evtUuid = evt.getHeader('Unique-ID');
if (evtUuid !== channelUuid) return;
const evtFile =
evt.getHeader('Playback-File-Path') ||
evt.getHeader('File-Path') ||
evt.getHeader('Application-Data') ||
'';
if (evtFile.includes(wavPath)) {
eslConn.removeListener('esl::event::PLAYBACK_STOP::*', listener);
resolve();
}
};
eslConn.on('esl::event::PLAYBACK_STOP::*', listener);
});
await eslBgapi(`uuid_broadcast ${channelUuid} ${wavPath} aleg`);
await playbackComplete;
fs.unlink(wavPath, () => {});
}
async function loop() {
playing = true;
while (playableQueue.length > 0) {
const { wavPath, onPlayStart } = playableQueue.shift();
if (onPlayStart) onPlayStart();
await broadcastAndWait(wavPath);
}
playing = false;
checkIdle();
}
return {
reservePhrase() {
pendingSynth++;
},
enqueue(phraseN, wavPath, onPlayStart) {
pendingSynth--;
waiting.set(phraseN, { wavPath, onPlayStart });
drainWaiting();
if (!playing && playableQueue.length > 0) loop();
},
cancelPhrase(phraseN) {
pendingSynth--;
if (phraseN === nextExpected) {
nextExpected++;
drainWaiting();
}
checkIdle();
},
waitUntilIdle() {
return new Promise((resolve) => {
if (!playing &&
playableQueue.length === 0 &&
pendingSynth === 0 &&
waiting.size === 0) {
return resolve();
}
onIdle = resolve;
});
},
resetPhraseCursor() {
nextExpected = 1;
waiting.clear();
},
};
}Two non-obvious things here that I want to flag because they bit me hard.
The PLAYBACK_STOP event listener has to match on file path, not just channel UUID. When you queue multiple WAVs back-to-back, FreeSWITCH fires PLAYBACK_STOP events for each one. They all carry the same channel UUID. If your listener resolves on UUID match alone, the first PLAYBACK_STOP resolves the listener for whichever WAV is currently being awaited — even if it was actually fired by a different WAV. The result is audio playing in the wrong order. You have to match on the file path embedded in Playback-File-Path (different FreeSWITCH versions may use slightly different header names; the code tries the three most common).
Phrases can synthesize in parallel, but they must play in strict order. If the LLM produces “I’m doing great, thanks!” and “How about you?” as two phrases, both get shipped to TTS at roughly the same time. The shorter second phrase (3 words) finishes synthesizing before the longer first one (4 words plus emphasis). If you enqueue them as they finish, the user hears “How about you? I’m doing great, thanks!” The fix is the nextExpected cursor: phrases are stored in a waiting map by their phrase number, and only released to the playable queue in strict numeric order.
The reservation pattern (reservePhrase / enqueue / cancelPhrase) is what makes waitUntilIdle() honest. Without it, you’d think the queue was idle the moment your last enqueue finished — but if a phrase hasn’t yet finished synthesizing, the queue actually still has work to do. Tracking “phrases reserved but not yet enqueued” alongside “phrases enqueued but not yet played” gives us a clean idle signal.
The per-call handler is where it all comes together:
javascript
wss.on('connection', async (ws, req) => {
const callId = `call-${Date.now()}`;
console.log(`\n[${callId}] FreeSWITCH connected from ${req.socket.remoteAddress}`);
const conversation = [{ role: 'system', content: SYSTEM_PROMPT }];
let turnNumber = 0;
let speaking = false;
let currentTurn = null;
let channelUuid = null;
let dgSttReady = false;
let playbackQueue = null;
let pendingUtterance = null;
let utteranceBuf = '';
ws.on('message', (data, isBinary) => {
if (!isBinary) {
try {
const msg = JSON.parse(data.toString());
if (msg.type === 'start' && msg.uuid) {
channelUuid = msg.uuid;
playbackQueue = makePlaybackQueue(callId, channelUuid);
console.log(`[${callId}] channel UUID: ${channelUuid}`);
}
} catch {}
return;
}
if (dgSttReady && dgStt.socket?.readyState === 1) {
dgStt.socket.send(data);
}
});
const dgStt = await deepgram.listen.v1.connect({
model: 'nova-3',
encoding: 'linear16',
sample_rate: SAMPLE_RATE,
channels: CHANNELS,
punctuate: true,
interim_results: true,
endpointing: 300,
utterance_end_ms: 1000,
vad_events: true,
smart_format: false,
});The Deepgram STT config deserves explanation because it’s the difference between a usable agent and one that interrupts you constantly.
endpointing: 300 tells Deepgram to emit is_final results after 300ms of silence. That sounds aggressive and it is — but we don’t trigger LLM calls on is_final events. Instead we accumulate finals and only act on UtteranceEnd events, which fire after utterance_end_ms: 1000 (one full second of silence). That’s the difference between a transient pause and “the user has actually finished their thought.”
smart_format: false is essential. With it on, Deepgram inserts punctuation aggressively — and a phrase like “Hi. How are you today?” gets split at the period into two separate finals. The LLM responds to “Hi” before you’ve finished saying “How are you today?” and the conversation runs a turn behind reality. Turning smart_format off at the cost of slightly less polished transcripts is a clear win for conversational flow.
The transcript handler accumulates final fragments and triggers turns only on real utterance ends:
dgStt.on('message', async (data) => {
if (data.type === 'UtteranceEnd') {
if (!utteranceBuf.trim()) return;
const fullUtterance = utteranceBuf.trim();
utteranceBuf = '';
console.log(`[${callId}] UTTERANCE: "${fullUtterance}"`);
if (!channelUuid) return;
if (speaking) {
console.log(`[${callId}] (queued — agent still speaking)`);
pendingUtterance = fullUtterance;
return;
}
await handleUserTurn(fullUtterance);
while (pendingUtterance && !speaking) {
const next = pendingUtterance;
pendingUtterance = null;
console.log(`[${callId}] processing queued: "${next}"`);
await handleUserTurn(next);
}
return;
}
if (data.type !== 'Results') return;
const transcript = data.channel?.alternatives?.[0]?.transcript;
if (!transcript) return;
if (data.is_final) {
utteranceBuf += (utteranceBuf ? ' ' : '') + transcript;
console.log(`[${callId}] (final fragment): "${transcript}"`);
} else {
console.log(`[${callId}] interim: "${transcript}"`);
}
});The pendingUtterance slot handles a real-world case: the user starts talking while the agent is still speaking. We don’t have barge-in yet (Part 5), so we can’t interrupt the agent. But we can remember what the user said. When the agent finishes its current turn, we process the queued utterance immediately. Last-write-wins — if the user says multiple things while the agent is talking, only the most recent counts (they probably restated or refined).
The actual LLM-driven turn handler:
async function handleUserTurn(userText) {
turnNumber++;
currentTurn = {
n: turnNumber, startedAt: Date.now(),
llmFirstAt: null, firstPlayStartAt: null,
completedAt: null, phraseCount: 0,
};
console.log(`[${callId}] turn ${turnNumber} start`);
playbackQueue.resetPhraseCursor();
conversation.push({ role: 'user', content: userText });
speaking = true;
let fullResponse = '';
try {
const stream = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: conversation,
stream: true,
});
let phraseBuf = '';
for await (const chunk of stream) {
if (!currentTurn.llmFirstAt) {
currentTurn.llmFirstAt = Date.now();
const dt = currentTurn.llmFirstAt - currentTurn.startedAt;
console.log(`[${callId}] LLM first token at +${dt}ms`);
}
const delta = chunk.choices?.[0]?.delta?.content;
if (!delta) continue;
phraseBuf += delta;
fullResponse += delta;
if (/[.!?]$/.test(phraseBuf.trim()) ||
(/,$/.test(phraseBuf.trim()) && phraseBuf.length > 40)) {
shipPhrase(phraseBuf.trim());
phraseBuf = '';
}
}
if (phraseBuf.trim()) shipPhrase(phraseBuf.trim());
conversation.push({ role: 'assistant', content: fullResponse });
const MAX_TURNS = 10;
while (conversation.length > MAX_TURNS * 2 + 1) {
conversation.splice(1, 2);
}
await playbackQueue.waitUntilIdle();
currentTurn.completedAt = Date.now();
const total = currentTurn.completedAt - currentTurn.startedAt;
console.log(`[${callId}] turn ${turnNumber} complete (${total}ms total)`);
speaking = false;
} catch (err) {
console.error(`[${callId}] turn ${turnNumber} error:`, err.message);
speaking = false;
currentTurn = null;
}
}
function shipPhrase(text) {
if (!currentTurn) return;
currentTurn.phraseCount++;
const phraseN = currentTurn.phraseCount;
const turnRef = currentTurn;
playbackQueue.reservePhrase();
synthesizePhraseToWav(text, callId, turnRef.n, phraseN)
.then((wavPath) => {
playbackQueue.enqueue(phraseN, wavPath, () => {
if (!turnRef.firstPlayStartAt) {
turnRef.firstPlayStartAt = Date.now();
const dt = turnRef.firstPlayStartAt - turnRef.startedAt;
console.log(`[${callId}] first audio playing at +${dt}ms`);
}
});
})
.catch((err) => {
console.error(`[${callId}] phrase ${phraseN} synth failed:`, err.message);
playbackQueue.cancelPhrase(phraseN);
});
}The phrase boundary regex is the heart of the latency optimization. Instead of waiting for the LLM to finish streaming all 30+ words of its response before starting synthesis, we ship each sentence (or comma clause longer than 40 characters) to TTS the moment the LLM produces the punctuation. By the time the LLM finishes streaming, the first phrase is often already playing.
Conversation memory is dead simple: every user message and assistant response gets appended to the conversation array, which we send to GPT-4o-mini on every turn. We trim to the last 10 user/assistant pairs to bound token usage. For most calls this is plenty — voice conversations rarely span more than a dozen turns before they end naturally.
The greeting helper is a small shortcut for the no-LLM case (we have a fixed greeting string):
async function speakResponse(text, isGreeting = false) {
if (isGreeting) {
turnNumber++;
currentTurn = {
n: turnNumber, startedAt: Date.now(),
llmFirstAt: Date.now(),
firstPlayStartAt: null, completedAt: null, phraseCount: 0,
};
console.log(`[${callId}] turn ${turnNumber} (greeting) start`);
}
playbackQueue.resetPhraseCursor();
speaking = true;
shipPhrase(text);
if (!isGreeting) conversation.push({ role: 'assistant', content: text });
await playbackQueue.waitUntilIdle();
currentTurn.completedAt = Date.now();
const total = currentTurn.completedAt - currentTurn.startedAt;
console.log(`[${callId}] turn ${currentTurn.n} complete (${total}ms total)`);
speaking = false;
}
And the lifecycle plumbing:
javascript
ws.on('close', () => {
console.log(`[${callId}] FreeSWITCH connection closed`);
if (dgStt.socket?.readyState === 1) dgStt.socket.close();
});
ws.on('error', (err) => console.error(`[${callId}] WebSocket error:`, err.message));
});
(async () => {
await connectEsl();
console.log(`Listening for FreeSWITCH audio on ws://0.0.0.0:${PORT}`);
})().catch(err => {
console.error('Boot failed:', err.message);
process.exit(1);
});Worth noting: the per-connection handler also calls a small bootstrapping sequence that opens the Deepgram STT connection and delivers the greeting. That’s part of the complete file in the next step.
Step 5b: The complete file, ready to copy
Pasting the snippets above in order will get you 90% of the way there, but it’s easy to miss a closure boundary or miss the bootstrap that runs the greeting on call connect. Here’s the complete /opt/audio-fork-server/audio-fork-server.js as one paste-ready block:
javascript
// audio-fork-server.js (Part 4 — closed loop voice agent, uuid_broadcast playback)
//
// Caller speaks → Deepgram STT → OpenAI streaming → Deepgram TTS → caller hears.
// Playback path: Node writes a .wav file then asks FreeSWITCH to play it via
// the Event Socket's uuid_broadcast command.
//
// Reads from process.env: DEEPGRAM_API_KEY, OPENAI_API_KEY, FS_ESL_PASSWORD
const fs = require('fs');
const { WebSocketServer } = require('ws');
const { DeepgramClient } = require('@deepgram/sdk');
const OpenAI = require('openai');
const esl = require('modesl');
const PORT = 8080;
const SAMPLE_RATE = 8000;
const CHANNELS = 1;
const DG_KEY = process.env.DEEPGRAM_API_KEY;
const OPENAI_KEY = process.env.OPENAI_API_KEY;
const ESL_PASS = process.env.FS_ESL_PASSWORD;
if (!DG_KEY) { console.error('ERROR: DEEPGRAM_API_KEY not set.'); process.exit(1); }
if (!OPENAI_KEY) { console.error('ERROR: OPENAI_API_KEY not set.'); process.exit(1); }
if (!ESL_PASS) { console.error('ERROR: FS_ESL_PASSWORD not set.'); process.exit(1); }
const deepgram = new DeepgramClient({ apiKey: DG_KEY });
const openai = new OpenAI({ apiKey: OPENAI_KEY });
const wss = new WebSocketServer({ port: PORT });
const SYSTEM_PROMPT =
'You are a helpful voice agent. Keep responses brief and conversational — ' +
'typically 1-2 sentences. Speak naturally as if on a phone call. ' +
'Avoid markdown, lists, or formatting.';
const GREETING = 'Hi there! How can I help you today?';
// ----- Shared ESL connection ---------------------------------------------
let eslConn = null;
let eslReady = false;
function connectEsl() {
return new Promise((resolve, reject) => {
const conn = new esl.Connection('127.0.0.1', 8021, ESL_PASS, () => {
console.log('ESL connected to FreeSWITCH');
conn.events('plain', 'PLAYBACK_STOP CHANNEL_HANGUP', () => {
eslConn = conn;
eslReady = true;
resolve(conn);
});
});
conn.on('error', (err) => {
console.error('ESL error:', err);
eslReady = false;
reject(err);
});
});
}
function eslBgapi(cmd) {
return new Promise((resolve, reject) => {
if (!eslReady) return reject(new Error('ESL not ready'));
eslConn.bgapi(cmd, (res) => resolve(res?.getBody?.() || ''));
});
}
// ----- WAV writer --------------------------------------------------------
function writeWav(filepath, pcm, rate, channels, bits) {
const byteRate = rate * channels * (bits / 8);
const blockAlign = channels * (bits / 8);
const header = Buffer.alloc(44);
header.write('RIFF', 0);
header.writeUInt32LE(36 + pcm.length, 4);
header.write('WAVE', 8);
header.write('fmt ', 12);
header.writeUInt32LE(16, 16);
header.writeUInt16LE(1, 20);
header.writeUInt16LE(channels, 22);
header.writeUInt32LE(rate, 24);
header.writeUInt32LE(byteRate, 28);
header.writeUInt16LE(blockAlign, 32);
header.writeUInt16LE(bits, 34);
header.write('data', 36);
header.writeUInt32LE(pcm.length, 40);
fs.writeFileSync(filepath, Buffer.concat([header, pcm]));
}
// ----- Synthesize one phrase to a WAV ------------------------------------
async function synthesizePhraseToWav(text, callId, turnN, phraseN) {
const tts = await deepgram.speak.v1.connect({
model: 'aura-2-thalia-en',
encoding: 'linear16',
sample_rate: SAMPLE_RATE,
});
const audioChunks = [];
let resolveFlushed;
const flushedPromise = new Promise(r => { resolveFlushed = r; });
tts.on('open', () => {
tts.socket.addEventListener('message', async (event) => {
const data = event.data;
if (data instanceof Blob) {
audioChunks.push(Buffer.from(await data.arrayBuffer()));
} else if (typeof data === 'string') {
try {
const msg = JSON.parse(data);
if (msg.type === 'Flushed') {
tts.socket.close();
resolveFlushed();
}
} catch {}
}
});
});
tts.on('error', (err) => console.error(`[${callId}] TTS error:`, err));
tts.connect();
await tts.waitForOpen();
tts.socket.send(JSON.stringify({ type: 'Speak', text }));
tts.socket.send(JSON.stringify({ type: 'Flush' }));
await flushedPromise;
const wavPath = `/tmp/agent-${callId}-${turnN}-${phraseN}.wav`;
writeWav(wavPath, Buffer.concat(audioChunks), SAMPLE_RATE, CHANNELS, 16);
return wavPath;
}
// ----- Per-call playback queue -------------------------------------------
function makePlaybackQueue(callId, channelUuid) {
const playableQueue = [];
const waiting = new Map();
let playing = false;
let pendingSynth = 0;
let nextExpected = 1;
let onIdle = null;
function checkIdle() {
if (!playing &&
playableQueue.length === 0 &&
pendingSynth === 0 &&
waiting.size === 0 &&
onIdle) {
const cb = onIdle;
onIdle = null;
cb();
}
}
function drainWaiting() {
while (waiting.has(nextExpected)) {
const entry = waiting.get(nextExpected);
waiting.delete(nextExpected);
playableQueue.push(entry);
nextExpected++;
}
}
async function broadcastAndWait(wavPath) {
const playbackComplete = new Promise((resolve) => {
const listener = (evt) => {
const evtUuid = evt.getHeader('Unique-ID');
if (evtUuid !== channelUuid) return;
const evtFile =
evt.getHeader('Playback-File-Path') ||
evt.getHeader('File-Path') ||
evt.getHeader('Application-Data') ||
'';
if (evtFile.includes(wavPath)) {
eslConn.removeListener('esl::event::PLAYBACK_STOP::*', listener);
resolve();
}
};
eslConn.on('esl::event::PLAYBACK_STOP::*', listener);
});
await eslBgapi(`uuid_broadcast ${channelUuid} ${wavPath} aleg`);
await playbackComplete;
fs.unlink(wavPath, () => {});
}
async function loop() {
playing = true;
while (playableQueue.length > 0) {
const { wavPath, onPlayStart } = playableQueue.shift();
if (onPlayStart) onPlayStart();
await broadcastAndWait(wavPath);
}
playing = false;
checkIdle();
}
return {
reservePhrase() {
pendingSynth++;
},
enqueue(phraseN, wavPath, onPlayStart) {
pendingSynth--;
waiting.set(phraseN, { wavPath, onPlayStart });
drainWaiting();
if (!playing && playableQueue.length > 0) loop();
},
cancelPhrase(phraseN) {
pendingSynth--;
if (phraseN === nextExpected) {
nextExpected++;
drainWaiting();
}
checkIdle();
},
waitUntilIdle() {
return new Promise((resolve) => {
if (!playing &&
playableQueue.length === 0 &&
pendingSynth === 0 &&
waiting.size === 0) {
return resolve();
}
onIdle = resolve;
});
},
resetPhraseCursor() {
nextExpected = 1;
waiting.clear();
},
};
}
// ----- Boot --------------------------------------------------------------
(async () => {
await connectEsl();
console.log(`Listening for FreeSWITCH audio on ws://0.0.0.0:${PORT}`);
console.log(`Deepgram client initialized (SDK v5).`);
console.log(`OpenAI client initialized.`);
})().catch(err => {
console.error('Boot failed:', err.message);
process.exit(1);
});
// ----- Per-call handler --------------------------------------------------
wss.on('connection', async (ws, req) => {
const callId = `call-${Date.now()}`;
console.log(`\n[${callId}] FreeSWITCH connected from ${req.socket.remoteAddress}`);
const conversation = [{ role: 'system', content: SYSTEM_PROMPT }];
let turnNumber = 0;
let speaking = false;
let currentTurn = null;
let channelUuid = null;
let dgSttReady = false;
let playbackQueue = null;
let pendingUtterance = null;
let utteranceBuf = '';
ws.on('message', (data, isBinary) => {
if (!isBinary) {
try {
const msg = JSON.parse(data.toString());
if (msg.type === 'start' && msg.uuid) {
channelUuid = msg.uuid;
playbackQueue = makePlaybackQueue(callId, channelUuid);
console.log(`[${callId}] channel UUID: ${channelUuid}`);
}
} catch {}
return;
}
if (dgSttReady && dgStt.socket?.readyState === 1) {
dgStt.socket.send(data);
}
});
const dgStt = await deepgram.listen.v1.connect({
model: 'nova-3',
encoding: 'linear16',
sample_rate: SAMPLE_RATE,
channels: CHANNELS,
punctuate: true,
interim_results: true,
endpointing: 300,
utterance_end_ms: 1000,
vad_events: true,
smart_format: false,
});
dgStt.on('open', () => {
console.log(`[${callId}] Deepgram STT opened`);
dgSttReady = true;
});
dgStt.on('message', async (data) => {
if (data.type === 'UtteranceEnd') {
if (!utteranceBuf.trim()) return;
const fullUtterance = utteranceBuf.trim();
utteranceBuf = '';
console.log(`[${callId}] UTTERANCE: "${fullUtterance}"`);
if (!channelUuid) return;
if (speaking) {
console.log(`[${callId}] (queued — agent still speaking)`);
pendingUtterance = fullUtterance;
return;
}
await handleUserTurn(fullUtterance);
while (pendingUtterance && !speaking) {
const next = pendingUtterance;
pendingUtterance = null;
console.log(`[${callId}] processing queued: "${next}"`);
await handleUserTurn(next);
}
return;
}
if (data.type !== 'Results') return;
const transcript = data.channel?.alternatives?.[0]?.transcript;
if (!transcript) return;
if (data.is_final) {
utteranceBuf += (utteranceBuf ? ' ' : '') + transcript;
console.log(`[${callId}] (final fragment): "${transcript}"`);
} else {
console.log(`[${callId}] interim: "${transcript}"`);
}
});
dgStt.on('error', (err) => console.error(`[${callId}] STT error:`, err));
dgStt.on('close', () => console.log(`[${callId}] STT closed`));
dgStt.connect();
try {
await dgStt.waitForOpen();
} catch (err) {
console.error(`[${callId}] STT failed to open:`, err.message);
ws.close();
return;
}
// Wait briefly for the channel UUID metadata to arrive before greeting
await new Promise(r => setTimeout(r, 200));
await speakResponse(GREETING, /*isGreeting=*/ true);
async function handleUserTurn(userText) {
turnNumber++;
currentTurn = {
n: turnNumber, startedAt: Date.now(),
llmFirstAt: null, firstPlayStartAt: null,
completedAt: null, phraseCount: 0,
};
console.log(`[${callId}] turn ${turnNumber} start`);
playbackQueue.resetPhraseCursor();
conversation.push({ role: 'user', content: userText });
speaking = true;
let fullResponse = '';
try {
const stream = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: conversation,
stream: true,
});
let phraseBuf = '';
for await (const chunk of stream) {
if (!currentTurn.llmFirstAt) {
currentTurn.llmFirstAt = Date.now();
const dt = currentTurn.llmFirstAt - currentTurn.startedAt;
console.log(`[${callId}] LLM first token at +${dt}ms`);
}
const delta = chunk.choices?.[0]?.delta?.content;
if (!delta) continue;
phraseBuf += delta;
fullResponse += delta;
if (/[.!?]$/.test(phraseBuf.trim()) ||
(/,$/.test(phraseBuf.trim()) && phraseBuf.length > 40)) {
shipPhrase(phraseBuf.trim());
phraseBuf = '';
}
}
if (phraseBuf.trim()) shipPhrase(phraseBuf.trim());
conversation.push({ role: 'assistant', content: fullResponse });
const MAX_TURNS = 10;
while (conversation.length > MAX_TURNS * 2 + 1) {
conversation.splice(1, 2);
}
await playbackQueue.waitUntilIdle();
currentTurn.completedAt = Date.now();
const total = currentTurn.completedAt - currentTurn.startedAt;
console.log(`[${callId}] turn ${turnNumber} complete (${total}ms total)`);
speaking = false;
} catch (err) {
console.error(`[${callId}] turn ${turnNumber} error:`, err.message);
speaking = false;
currentTurn = null;
}
}
function shipPhrase(text) {
if (!currentTurn) return;
currentTurn.phraseCount++;
const phraseN = currentTurn.phraseCount;
const turnRef = currentTurn;
playbackQueue.reservePhrase();
synthesizePhraseToWav(text, callId, turnRef.n, phraseN)
.then((wavPath) => {
playbackQueue.enqueue(phraseN, wavPath, () => {
if (!turnRef.firstPlayStartAt) {
turnRef.firstPlayStartAt = Date.now();
const dt = turnRef.firstPlayStartAt - turnRef.startedAt;
console.log(`[${callId}] first audio playing at +${dt}ms`);
}
});
})
.catch((err) => {
console.error(`[${callId}] phrase ${phraseN} synth failed:`, err.message);
playbackQueue.cancelPhrase(phraseN);
});
}
async function speakResponse(text, isGreeting = false) {
if (isGreeting) {
turnNumber++;
currentTurn = {
n: turnNumber, startedAt: Date.now(),
llmFirstAt: Date.now(),
firstPlayStartAt: null, completedAt: null, phraseCount: 0,
};
console.log(`[${callId}] turn ${turnNumber} (greeting) start`);
}
playbackQueue.resetPhraseCursor();
speaking = true;
shipPhrase(text);
if (!isGreeting) conversation.push({ role: 'assistant', content: text });
await playbackQueue.waitUntilIdle();
currentTurn.completedAt = Date.now();
const total = currentTurn.completedAt - currentTurn.startedAt;
console.log(`[${callId}] turn ${currentTurn.n} complete (${total}ms total)`);
speaking = false;
}
ws.on('close', () => {
console.log(`[${callId}] FreeSWITCH connection closed`);
if (dgStt.socket?.readyState === 1) dgStt.socket.close();
});
ws.on('error', (err) => console.error(`[${callId}] WebSocket error:`, err.message));
});Save it, you’re ready to run.
Step 6: Run it
bash
cd /opt/audio-fork-server
sudo -E node audio-fork-server.jsExpected output:
ESL connected to FreeSWITCH
Listening for FreeSWITCH audio on ws://0.0.0.0:8080
Deepgram client initialized (SDK v5).
OpenAI client initialized.
Place a call to extension 9999. You’ll see the agent greeting log, hear “Hi there! How can I help you today?” through your softphone, and you can have a conversation. Try a multi-turn exchange to verify memory works:
You: “Hi, can you give me a recipe for dinner rolls?”
Agent: “Sure! Are you looking for a specific type of dinner roll, like fluffy, whole wheat, or something else?”
You: “Fluffy.”
Agent: “Great choice! You’ll need flour, yeast, butter, sugar, milk, and eggs…”
The “Fluffy.” response only makes sense if the agent remembers the previous turn — that’s conversation memory working.
What the latency numbers actually look like
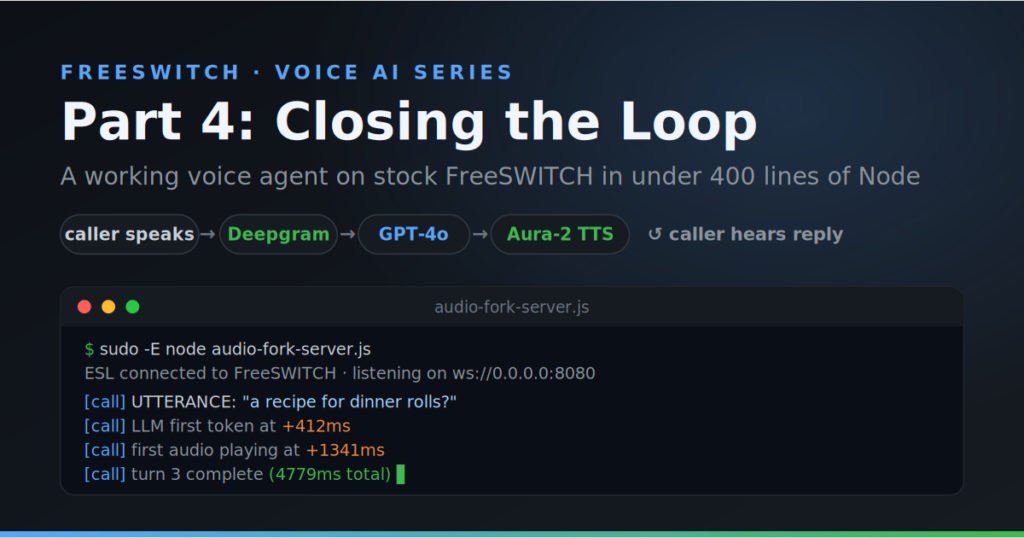
Here’s an actual log from a five-turn conversation:
turn 1 (greeting): 1475ms first audio 3825ms total
turn 2 (long answer): 4174ms first audio 14762ms total
turn 3: 1766ms first audio 4779ms total
turn 4: 1408ms first audio 7133ms total
turn 5: 1341ms first audio 5139ms total
Median first-audio latency lands right around 1.4 seconds. Our turn 2 outlier (at over 4 seconds) came from a question that elicited a 27-word response with zero early punctuation. Because of that, our phrase-boundary logic didn’t trigger a chunk until nearly 3 seconds into the LLM stream. While we could tighten those phrase boundaries to force faster execution, doing so risks creating choppy, unnatural cadences—a tuning optimization for another day. Ultimately, if your primary goal is speed-to-market, leaning on an established orchestration framework like Pipecat or a specialized voice vendor starts to look highly attractive!
For comparison, OpenAI’s Realtime API demo typically lands around 600-900ms first-audio. We’re not close to that, but we’re using off-the-shelf APIs from three different vendors (Deepgram STT, OpenAI LLM, Deepgram TTS) connected by a Node server going through FreeSWITCH’s standard playback machinery. Realtime APIs win by collapsing those four hops into one, at the cost of vendor lock-in.
What this doesn’t have
This is a primer. Several things production agents need are deliberately out of scope:
Barge-in. If you start talking while the agent is talking, you have to wait for it to finish. Real agents detect user voice activity and immediately stop their own playback. We have the building blocks (pendingUtterance, the playback queue’s cancelPhrase) but the integration is genuinely tricky.
Error handling. The LLM call has a try/catch. The TTS path doesn’t have retry logic. The ESL connection doesn’t auto-reconnect on failure. None of this matters for a tutorial demo. All of it matters in production.
Service user and systemd unit. Right now, we’re running the server with sudo -E node. That’s fine for development, awful for production. Setting up a dedicated service user with the right capabilities and a proper systemd unit is the right way to go.
Observability. Latency markers in stdout are nice. Real metrics emitted to Prometheus or OpenTelemetry are what you actually want.
Multi-call testing. The architecture supports concurrent calls (one Node process, one shared ESL connection, per-call WebSocket and Deepgram and OpenAI state). We’ve only validated one call at a time.
Be First to Comment